자율주행 컴퓨터 : 범용 계산을 위한 CPU, GPU, 고속 뉴럴네트워크 계산을 위한 가속시
인지 소프트웨어 : 주변 환경 인지 수행을 위한 알고리즘
2. 자율주행 통합 인지 기능
센서 데이터의 전처리 및 동기화
동적 객체 검출
동적 객체 추적
동적 객체의 의도 및 미래 위치 예측(움직임 분석)
주행 관련 정적 객체 검출 -> 맵매칭 기반 측위에 활용
차선, 도로 등의 영역 검출 -> 맵매칭 기반 측위에 활용
전방 영역 또는 장애물 등의 거리 지도 생성
3. 센서별 인지 기술
카메라 기반의 인지 기술 -주로 CNN 등의 딥러닝 모델을 카메라 영상에 적용 -> 동적 객체와 정적 객체 검출, 추적 -기존에는 물체의 크기나 범퍼 등의 정보를 이용하여 물체의 거리 측정
최근에는 카메라 영상 기반 거리 추정(딥러닝 기술 적용, 스테레오 카메라 사용)
카메라 영상으로부터 차선, 도로, 인도 등의 영역 검출
객체의 움직임을 분석하여 주변 차량 또는 보행자의 경로 예측
레이더 기반의 인지 기술 -수신된 전자기 신호 분석 -> 조감도 영역에서 동적 객체의 위치와 속도 측정 -물체의 움직임 추적 및 물체 ID 부여 -검출 알고리즘은 물체와 클러터에 의한 허상을 구분할 수 있어야함
라이다 기반의 인지 기술 -포인트 클라우드 데이터를 취득하여 분석 -> 3차원 영역에서 동적 객체의 위치 검출, 추적 -고해상도 라이다의 경우 : 동적 객체의 정확한 종류, 거리 정보 등을 얻을 수 있음, 전방 영역 또는 장애물까지의 거리를 정확히 추정해 낼 수 있음
센서들은 다 장단점이 있기 때문에 센서 융합 필요
복합 센서로부터 얻은 정보 융합 후 강인하고 신뢰성 높은 인지 기능 수행 가능
[자율주행 인지를 위한 AI 기술 심화]
1. AI 기술의 발전
딥러닝 : 딥뉴럴 네트워크, 계층이 여러개인 인공신경망
역사 -1960~1990 : 활발한 연구 진행, 뉴럴네트워크 이론척 기초 확립, 하드웨어 성능이 따라주지 못함 -1990~2010 : 인공지능의 암흑기, 뉴럴네트워크 모델이 실용적이지 않다고 생각한 연구자들, 연구자들의 관심이 뉴럴네트워크 모델에서 Support Vector Machine이나 커널 방법으로 이동 -2008 : 토론토 대학 Geoffrey Hinton 교수의 논문 발표(딥뉴럴네트워크의 학습 가능) -2012 : 이미지넷 챌린지(1000개 종류의 영상 분류 경진 대회)에서 알렉스넷(AlexNet)이라고 불리는 딥뉴럴 네트워크 구조가 압도적 1등 차지함 → 딥러닝 기술 주목받음, GPU 발전, 빅데이터 기술 발전 -2012~현재 : 인공지능 분야의 전성기, 알파고, GAN, GPT3 등 뛰어난 딥러닝 모델들 나옴, 눈부신 발전, 다양한 분야에 딥러닝 기술 적용되고 있음
2. 자율주행 인지를 위한 딥러닝
딥러닝 구조 : 하나 이상의 계층으로 이루어진 인공신경망 모델(뉴럴네트워크) -복잡한 입력과 출력과의 관계를 근사화하기 위한 모델 -딥러닝 구조에서 계층 사이에 곱해지는 계수들이 딥러닝 구조를 결정함
딥러닝 학습 과정 : 트레이닝, 인퍼런스
트레이닝 : 정답을 달아놓은(라벨링) 트레이닝 데이터를 사용하여 모델 훈련
인퍼런스 : 트레이닝이 끝나면 자율주행차에 탑재하여 실제 인지 기능 수행
센서 데이터를 처리하기 위한 기본적인 딥러닝 모델 -CNN(Convolutional Neural Network) : 2차원 영상데이터로부터 유용한 특징값을 뽑아내기 위한 뉴럴네트워크 구조, 물체 검출, 영역 검출, 거리 추정에 사용 -RNN(Recurrent Neural Network) : 시간적인 시계열 데이터로부터 유용한 특징값을 뽑아내기 위한 뉴럴네트워크 구조, LSTM 모델이 유명, 동적 객체의 움직임 예측에 사용 -PointNet(포인트넷) : 순서가 없는 점의 집합으로 되어 있는 데이터로부터 유용한 특징값을 뽑아내기 위한 뉴럴네트워크 구조, 라이다 데이터로부터 물체 검출에 사용
기본적인 딥러닝 이용시 -센서 데이터로부터 특징값 추출 → 검출, 영역 분할, 거리 추정 등의 복잡한 작업 수행 -자율주행에서는 센서 데이터의 차수가 높고 아주 복잡한 작업을 수행해야함 → 규모가 큰 딥러닝 모델 사용해야함 -> 트레이닝하기 위한 대용량의 학습 데이터 구축 필요
[자율주행 대규모 인지 데이터 관리 기술]
1. 자율주행 대규모 인지 데이터 관리 기술 개요
자율주행 인지를 위한 딥러닝 모델을 학습시키기 위해 엄청난 양의 트레이닝 데이터 필요
머신러닝 기술의 성능 : 학습 데이터가 많을수록 -> 머신러닝 성능 향상
일회성의 데이터 수집으로 학습한 모델로는 다양한 상황에 대해 대처 불가능
지속적이고 안정적인 모델을 위해서는 반복적인 데이터 관리 프로세스를 수행하는 플랫폼 필요
데이터 취득 → 라벨링→ 학습→ 검증→ 탑재
2. 대규모 인지 데이터 관리 기술 소개
자율주행 데이터 수집 -데이터 취득을 위한 전용 차량을 통한 학습 데이터 수집 -실제 자율주행차에서 수집된 데이터를 클라우드로 전송 -인프라, 엣지 등에 센서를 장착하여 데이터 취득
데이터 선별 및 검증 -데이터의 라벨링 과정에 많은 비용과 노력 소요 -현재 학습된 모델을 향상시키는데 도움이 되는 데이터만 선별 -능동학습(Active Learning) : 불확실성이 큰 데이터만을 라벨링하여 적은 수의 데이터만으로 학습 성능을 극대화시키는 전략 -선별한 데이터 라벨링 수행 후 검증 과정 중요(이유 : 데이터의 질이 학습 성능에 큰 영향을 끼치기 때문)
학습(트레이닝) -대규모의 학습 데이터를 이용하여 자율주행 인지 모델을 트레이닝 -클라우드에서 전용 딥러닝 하드웨어 사용(많은 연산 필요) -> 오랜 계산시간 소모 -> 딥러닝 구조 선정 및 하이퍼파라미터 튜닝
검증 및 테스트 -테스트 데이터를 이용한 인지 기능 테스트 -실제 도로에서의 시나리오별 자율주행 기능 검증 -시뮬레이션을 통한 인지 성능 테스트(디지털 트윈) -실제 자율주행차에 추가적으로 탑재하여섀도우 모드로 테스트
탑재 -검증이 된 자율주행 모델을 소프트웨어 OTA를 통해 차량에 탑재 -지속적으로 소프트웨어 관리 및 업데이트 수행
데이터 관리를 위한 플랫폼 구축 -클라우드를 중심으로 실시간으로 수집되는 대규모의 주행, 교통, 센서 데이터 관리 -증가하는 데이터의 규모를 다룰 수 있는 클라우드 서버 기술과 데이터베이스 확보 -라벨링에 의한 비용을 최대한 줄이는 솔루션 중요 -자율주행차와 클라우드가 정보를 주고받기 위한 통신 및 OTA 기술 중요
[카메라 캘리브레이션 심화]
1. 카메라 캘리브레이션 개요
카메라 캘리브레이션 : 월드 좌표계의 3차원 점과 대응하는 영상의 2차원 픽셀로의 변환 행렬 모델을 찾는 과정
카메라 내부 파라미터 -카메라 자체의 셋업에 관련된 파라미터 -카메라 좌표계와 카메라 영상의 픽셀값과의 대응 설명 -카메라 내부 파라미터에 영향을 미치는 것 : 초점거리, 렌즈 왜곡, 영상 중심값, 이미지 센서(Aspect Ratio, Skew Factor)
카메라 외부 파라미터 -3차원 카메라 좌표계를 3차원 월드 좌표계로 변환 -구성 : 회전 이동, 평행 이동
캘리브레이션 과정
2. 카메라 캘리브레이션 과정
-> But, 이것은 이상적인 핀홀 카메라 행렬 모델에서의 과정 -실제 렌즈 카메라에서는 렌즈의 왜곡을 보정하기 위한 캘리브레이션 수행 -방사형, 접선형 렌즈 왜곡이 있음
서로 대응되는 3D 월드 좌표계와 2D 이미지 픽셀의 점들을 이용
체커보드와 같은 반복적인 패턴을 카메라로 여러장의 영상을 찍어 3D 월드 좌표계와 2D 이미지 픽셀의 대응점들을 찾아 수행
체커보드
카메라 캘리브레이션 툴 사용 -> 영상에서 체커보드의 코너점 파악 -> 외부 파라미터와 내부 파라미터 계산
[카메라 기반 물체 검출 딥러닝 기술 심화]
1. 카메라 기반 물체 검출 기술 개요
카메라 영상에서 단일, 혹은 다중의 물체의 종류와 위치를 추정하는 기술
물체의 위치는 물체를 포함하는 2차원 바운딩 박스로 표현
CNN 사용 → 카메라 영상으로부터 추상적인 특징 지도 추출
CNN을 백본 네트워크(물체 검출을 위한 추상적인 특징을 네트워크로 사용)로 사용 → 추상화된 특징 지도를 추출→ 각 원소마다 앵커 박스(각 원소마다의 기준 박스) 이용→ 상대 변위 추정, 물체 분류 수행
2. 카메라 기반 물체 검출 딥러닝 기술
1차 검출기와 2차 검출기로 나뉨 예>YOLO, SSD, RetinaNet
RoI Pooling : 물체가 존재한다고 생각되는 영역의 특징값 추출 예>Faster RCNN, Mask R-CNN, Cascade R-CNN
3. 카메라 기반 물체 검출 딥러닝 기술
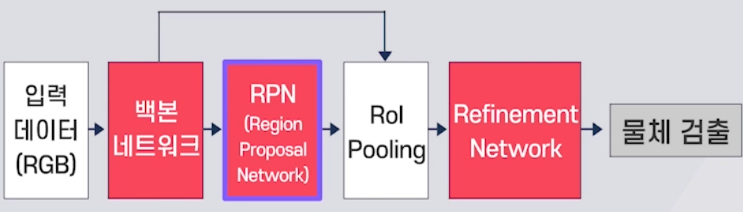
백본 네트워크 : 카메라 영사에서 원하는 특징값 추출, VGGNet, ResNet 등의 CNN 모델 사용, ImageNet 데이터셋으로 미리 훈련된 가중치를 초기값으로 사용
RPN(Region Proposal Network) : 백본 네트워크를 통해 나온 특징맵을 이용해 물체의 존재 유무와 위치 검출, 앵커 박스를 기준으로 하여 상대 변위 추정
ROI Pooling : RPN에서 출력된 박스를 이용하여 백본 네트워크에서 얻은 특징 지도로부터 해당 영역의 특징값 추출
Refinement Network : ROI Pooling을 통해 얻은 특징값을 이용해 물체의 정확한 종류 판별 및 위치 추정값 개선
4. 물체 검출 딥러닝 모델의 트레이닝 과정
물체의 바운딩박스 라벨링이 되어 있는 트레이닝 데이터 이용
손실함수를 최소가 되도록 종단간(end-to-end) 학습 수행
손실함수의 지역적 최소값을 찾아가야 함(Back Propagation 이용)
데이터 Augmentation 기법 : 학습해야 하는 파라미터 수에 비해 데이터의 갯수가 모자랄 때, 트레이닝 데이터를 인공적으로 가공, 추가적인 데이터셋 생성(좌우대칭, 확대및축소, 밝기조절, 회전, 노이즈추가 등)
5. 물체 검출기의 성능 평가
정답 박스와 출력 박스 사이에 겹치는 면적(IoU, intersection over union)을 기반으로 판별, 겹치는 면적 비율이 0.5 이상이면 정확하게 검출했다고 판단
물체검출기의 성능을 Mean Average Precision(mAP)를 기준으로 판별(Precision, Recall)
Precision : 물체라고 한것중에서 몇개나 맞았는가의 비율
Recall : 실제로 물체인것중에 몇개를 맞췄는가의 비율
Precision과 Recall은 반대 관계, Precision-Recall 커브를 적분한 값이 mAP값
[카메라 기반 물체 추적 딥러닝 기술 심화]
1. 카메라 기반 물체 추적 딥러닝 기술 개요
각 비디오 프레임에서 얻어진 물체 검출 결과를 추가적으로 처리하는 과정
각 프레임에서 얻은 검출 결과 연결(Association) -서로 인접한 프레임의 검출 결과를 같은 물체에 대해 연결하여 시간에 따른 물체의 움직임 추적 -추적하는 물체에 대해 트랙 ID 부과
연결된 검출 결과의 필터링 및 예측 -이전 프레임까지 추적하고 있는 물체 위치의 시퀀스인 트랙에 연결된 검출 결과를 추가하여 필터링 수행 -다음 프레임에서의 검출 결과 연결에 활용하기 위해 다음 프레임에 해당하는 물체 위치 예측
시간에 따라 두 과정이 서로 순환하면서 수행됨
과거에 딥러닝 모델은 대부분 물체 검출에만 적용되었으나 최근에는 물체 추적에도 활용되는 추세
딥러닝 기반의 미래의 물체 위치 예측 -기존 방법의 칼만필터 대신 딥러닝 모델을 사용하여 다음 프레임에서의 물체 필터링 및 예측
딥러닝을 이용한 물체 검출 결과 사이의 유사도 측정 -현재 물체 정보와 과거 물체 검출 결과를 딥뉴얼 네트워크를 통해 두 검출 결과의 유사성 판단 -딥러닝의 입력으로 검출 결과에 해당하는 특징값 및 박스 좌표 등 사용 가능
2. 카메라 기반 물체 추적 딥러닝 기술
물체의 움직임 예측 방법 사례 -추적 중인 물체의 검출 결과를 예측하기 위하여 T프레임에서의 CNN 특징 지도를 이용하여 T-1프레임까지 얻은 트랙의 박스 좌표 기준으로 움직임을 예측함 -T프레임에 얻은 영상을 CNN을 통과시켜 이전 프레임의 박스 좌표를 기반으로 해당하는 픽처를 추출한 후 T-1프레임의 박스 좌표를 기반으로 해당 영역 특징값 추출 -추출된 특징값을 기반으로 T-1프레임에서 T프레임으로 갈때 박스 좌표의 변화 추정
검출 결과 사이의 유사성 판단을 위한 딥러닝 기술 사례 -유사성을 측정하기 위하여 두쌍의 검출 결과를 Siamese network라고 불리는 CNN 네트워크를 적용하여 0부터 1사이의 값으로 유사도 출력 -모든 검출 결과 쌍에 대한 유사도를 테이블로 표현할 수 있음 -헝가리안 알고리즘을 적용하여 최종적인 연결 결과를 얻어냄
[카메라 기반 차선, 도로 영역 검출 딥러닝 기술 심화]
1. 카메라 기반 영역 검출 기술 개요
자율주행 중 동적 객체 검출 및 차선, 도로, 횡단보도 등 형태가 분명하지 않는 객체에 대한 인식도 필요
Semantic Segmentation : 카메라 영상 내에 있는 물체들을 의미 있는 단위로 분할하는 방법
영역 분할은 영상 또는 물체를 이루는 각 픽셀이 어느 카테고리에 속하는지 분류하는 것
Semantic Segmentation 기술을 적용하여 픽셀 단위의 차선, 도로, 횡단보도 등의 검출 가능
카메라 영상에 CNN을 적용하여 특징값을 추출하고 각 픽셀의 카테고리를 판별
영상에서 특정 공간에서의 픽셀이 어떤 카테고리에 속하는지에 대한 추상적인 정보 추출 중요
FCN : Convolution layers만을 적용하여 추상적인 공간 정보 생성
U-Net, DeepLAB : 인코더 디코더 구조를 사용하여, 인코더 구조에서 CNN을 이용해 추상화된 특징 지도를 추출하고 디코더 구조에서 Upsampling 또는 Deconvolution 과정을 통해 특징 지도의 크기 복원
2. 딥러닝 기반 차선 검출
차선 정보는 주행을 위한 정보로 사용 및 고정밀 지도 기반의 맵매칭을 위해 사용
차선 정보가 중간에 소실되거나 보이지 않는 경우에도 신뢰성 있는 차선 정보를 제공할 수 있어야 함
기존에는 RANSAC과 같은 고전적인 비전 알고리즘 적용
최근에는 CNN기반 차선 검출 방법의 활발한 연구 -FCN과 같이 카메라 영상에 Convolutional layers를 적용하여 차선에 대한 픽셀 별 특징값 추출 -로컬하게 표현된 특징값들을 이용하여 차선에 대한 Curve fitting 수행 -3차원에서의 도로 영역으로 Curve fitting한 결과를 투영하여 최종적인 차선 검출 결과 도출
도로 검출 기술 : 안전 주행을 위한 도로 정보 제공 및 고정밀 지도에서의 측위를 위한 맵매칭에 사용
Semantic Segmentation을 적용하여 운전 가능한 도로 영역 검출
[차세대 레이더 센서 기술 소개]
1. 차세대 레이더 센서 기술의 필요성
기존 레이더 센서의 장점 -전자기파의 특성으로 인해 주변의 환경 변화에 강인함 → 자율주행에서 중요하게 작용 -저렴한 가격으로 정확한 거리 정보 획득 가능
기존 레이더 센서의 단점 -횡방향의 해상도가 높지 않음 -주변 장애물에 의한 반사로 인해 발생하는 클러터 현상 → 오탐률이 다른 센서에 비해 높음
차세대 레이더 센서 개발의 필요성 -고해상도의 라이다 센서를 사용하면 레이더 센서의 단점이 극복되지만, 가격이 높음 -3단계 조건부 자율주행에서는 고가의 라이다를 장착하기 부담스러움 -문제를 해결하기 위한 두가지 전략 : 레이더의 해상도 및 성능 개선, 라이다의 비용 절감 -국내외 많은 회사가 새로운 타입의 레이더 센서 개발에 적극적으로 뛰어들고 있음
2. 차세대 레이더 센서 기술
고해상도 레이더 -많은 수의 배열 안테나를 수직, 수평으로 장착하는 MIMO(Multi-input Multi-output) 기술 사용 -4D 이미지 레이더 : 물체에 대한 4차원 정보(3차원 위치와 속도)를 포인트 클라우드의 형태로 제공
일반 레이더와 비교하여 4D 이미지 레이더의 장점 : 높은 해상도 -기존 저해상도 레이더는 물체의 검출 결과 및 신호를 조감도 영역에서만 표현하는 한계 있음 -고해상도 레이더는 라이다 정도의 높은 해상도는 아니지만, 기존 레이더의 단점 극복할 수 있음 -저렴한 가격과 물체의 속도 정보 제공
차세대 레이더 기술 연구 이슈 -안테나 원소들의 배열 및 배치, 설계 기술 -Multi dimension의 신호를 효과적으로 처리하기 위한 고속 신호처리 기술 -배열 안테나를 작게 구현할 수 있는 소형화 기술 -고해상도 카메라와의 센서융합 기술 -포인트 클라우드 형식의 데이터를 활용한 딥러닝 기반의 고성능 인지기술 개발
[레이더 기반 인지 기술과 딥러닝]
1. 레이더 센서 기반 인지 기술
기존에는 대부분 각 레이더 제조업체마다 고유의 인지를 위한 신호처리 기술에 대한 솔루션을 갖고 있음
최근에 고해상도 레이더가 개발되면서 딥러닝 기술을 이용한 인지 기술 연구
딥러닝을 이용한 카메라와 레이더와의 센서융합 기술 중요 -레이더 : 거리 측정이 정확하고 환경의 영향을 적게 받지만, 오탐률 높음 -카메라 : 해상도가 높고 물체 검출 성능이 뛰어나지만, 거리 측정이 부정확하고 환경에 영향을 많이 받음 -두 센서를 융합하여 서로의 단점 보완 연구 진행
2. 레이더 센서 기반 딥러닝 기술
물체 검출을 위해 딥러닝을 적용하는 두가지 접근 방법 -거리-도플러 영상을 기반으로 한 2차원 물체 검출 -포인트 클라우드 데이터를 이용한 3차원 물체 검출
레이더 센서 기반 인지 연구를 위한 데이터셋
[nuScenes] -1대의 32채널 라이다, 5대의 레이더, 6대의 카메라, IMU, GPS 센서 -Continental ARS 레이더 사용(77GHz 장거리, FMCW 방식) -1000개 종류의 배경에서 140만장의 카메라 영상과 레이더 데이터 제공 -23개 종류의 물체에 대한 3차원 박스가 라벨링 되어있음 -0.5초마다 6.5번의 레이더 스캐닝을 누적해서 포인트 클라우드 데이터 제공
[ASTYX HiRES2019] -Astyx 레이더, 2048x618 Point Grey 카메라, 벨로다인 16채널 라이다 -6개 종류의 물체에 대한 3차원 박스 라벨링 제공
3. 레이더 센서 기반 딥러닝 기술
딥러닝 기반 3차원 물체 검출 기술 -복셀 기반의 방법 : 3차원 영역을 작은 복셀 구조로 나누어 복셀 안의 포인트 데이터로부터 특징값 추출 후 3차원 CNN을 적용하여 물체 검출
- 2차원 투영기반의 방법 : 포인트 데이터를 전방 또는 조감도 영역의 다양한 영역으로 투영 후 2차원 CNN 모델을 적용하여 물체 검출
-포인트넷 기반의 방법 : 포인트 클라우드 데이터를 직접 처리할 수 있는 포인트넷으로 물체 검출
카메라, 레이더 센서 융합 방법 -카메라를 위주로 하여 물체 검출을 한 후 레이더 정보를 추가로 가져와서 거리 추정 -> 카메라 검출 성능에 영향을 받음 -카메라 영상과 레이더 센서로부터 딥러닝 모델을 적용해서 각각의 특징값을 추출한 후 직접 결합하고 추가적인 딥러닝을 적용해서 물체 검출 -> 센서 융합에 의한 높은 성능 개선 가능
[라이다 센서 심화]
1. 라이다 센서 개요
물체 주변에 고출력 레이저를 송수신하여 지연시간을 측정하여 거리 추정
주변 환경에 대한 3차원의 정밀한 스캐닝 작업 수행
습도에 대한 강인성을 높이기 위해 1550nm의 파장의 광원을 사용하는 라이다를 개발 중
라이다 센서의 종류 -기계식 라이다 : 라이다의 몸체 또는 부분을 전기 모터를 사용하여 기계식으로 회전시켜 360도, 장거리에 대한 환경인지 가능 -솔리드 스테이트 라이다 : optical phased array라고 불리는 배열 안테나 구조를 사용하여 기계적 회전 없이 배열 안테나 조절, 위상 조절을 통해 특정 방향으로 레이저 발사 및 송신 -MEMS 라이다 : MEMS 기술을 이용하여 반사 거울을 전자식으로 제어해서 넓은 영역 스캐닝
2.라이다 센서 데이터 기반 인지
[포인트 클라우드] : 라이다 센서로 취득한 3차원 점의 집합(라이다 센서로 취득한 정보)
라이다 센서 데이터는 물체 표면을 나타내는 3차원 점의 집합이 포인트 클라우드로 표현
최근 라이다 포인트 클라우드 데이터를 처리하여 물체 검출 및 환경 인지하는 딥러닝 기법 활발히 연구
라이다 기반 인지에서는 포인트 클라우드 데이터를 처리하여 3차원 환경정보를 얻어냄 -3차원 동적물체, 정적물체 검출, 추적 -차량 전방 등의 환경에 대한 거리 측정 -고정밀 지도 생성 및 맵매칭 기반 측위
2012년 공개된 KITTI 데이터셋을 시작으로 다양한 데이터셋 공개
제품 개발이나 상용화된 알고리즘을 만들기 위해서는 자체적인 데이터셋 수집 필요
[라이다 기반 3차원 물체 검출 딥러닝 기술 심화]
포인트 클라우드 기반 특징 추출 방법 중 2차원 평면으로 투영하는 방법이 성능이 저하되는 이유는? -양자화로 인한 정보 손실
1. 라이다 기반 3차원 물체 검출 기술 개요
3차원 물체 검출 : 물체의 3차원 위치 정보 제공
3차원 물체 검출의 출력 형태 -3차원 바운딩 박스 형태로 제공 : 3차원 박스 형태의 좌표 및 (x,y) 축의 회전 각도 제공 -조감도 영역에서의 2차원 박스 형태로 제공 : 박스의 회전 각도 제공
자율주행의 경로 계획 및 판단 시 정확한 3차원 동적 개체의 위치 정보 제공
카메라와 달리 라이다는 3차원 측정 정보를 제공하기 때문에 정확한 3차원 물체 검출 가능
라이다를 사용한 3차원 물체의 검출 원리 -포인트 클라우드 데이터는 2차원 배열로 이루어진 데이터와 다른 구조를 가지고 있어 기존의CNN 구조를 이용하기에 적합하지 않음 -포인트 클라우드 데이터로부터 특징값을 추출한 후 특징값을 이용해서 물체의 검출을 해야함
2. 라이다 기반 3차원 물체 검출 기술
2차원 평면 투영 방법 -포인트들을 전방 또는 조감도 영역으로 직접 투영하여 새로운 2차원 데이터를 만들어냄 -양자화로 인한 성능 저하 때문에 최근에는 많이 사용되지는 않음
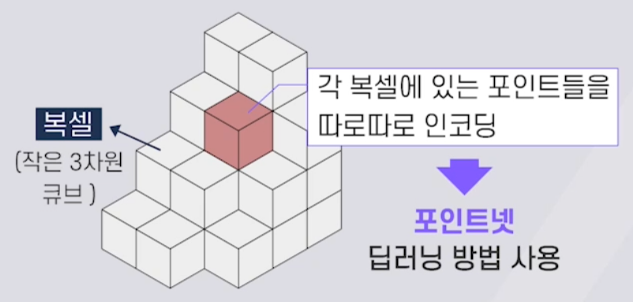
복셀 기반 표현 방법
-3차원 공간을 작은 복셀로 나누 후에 각 복셀에 들어있는 포인트들을 포인트넷을 적용하여 인코딩 -인베딩 벡터(3차원 복셀 구조안에 인코딩된 벡터)가 포함되어 있는 형태로 포인트 클라우드를 표현
포인트넷 사용 방법 -전체의 포인트 클라우드 집합에 포인트넷을 적용 -배경에 해당하는 포인트와 물체에 대한 포인트 분리 -물체에 해당하는 포인트들을 선택해내서 물체에 대한 특징값 추출 -복잡도가 높지만 정보의 손실 없이 모든 포인트 클라우드 데이터를 이용하여 정확한 검출 가능
3. 라이다 기반 3차원 물체 검출 기술 사례
복셀 기반의 방법 사례 : 세컨드, 포인트필라 -복셀 구조를 기반으로 포인트 데이터를 인코딩한 뒤 3차원 CNN이라는 구조를 적용해서 조감도 영역에서의 특징 지도 추출 -조감도 영역에서의 특징 지도를 기반으로 3차원 박스 검출
포인트넷 기반의 방법 사례 : 포인트 RCNN(2019년에 개발) -1단계 검출 : 물체와 배경에 해당하는 포인트를 구분한후 물체의 대략적인 위치 검출 -2단계 검출 : 대략적인 위치에 해당하는 포인트들을 다시 추출하여 1단계 물체 검출 결과의 정확도 향상
복셀과 포인트넷의 혼합방법 사례 : PV-RCNN -복셀 기반의 방법과 포인트넷 기반의 방법을 혼합하여 라이다 데이터의 풍부한 표현방식 제공
[라이다 기반 3차원 물체 추적 딥러닝 기술 심화]
1. 라이다 기반 3차원 물체 추적 기술 개요
3차원 물체 검출 결과를 같은 물체에 대해 연결하여 물체의 움직임을 시간에 따라 추적하는 기술
3차원 공간에서 새롭게 검출된 물체와 추적하고 있는 물체의 집합들의 유사성을 판단해서 물체 추적을 수행하고 물체 ID 부여
물체 추적 문제의 핵심은 다른 시간에 얻은 물체 검출 결과에서 같은 물체에 해당하는 검출 결과를 연결하는 Association 문제 -> 두개의 검출 결과에 대해 쌍에 대한 유사도 판별이 가능해야 함
라이다 기반 3차원 물체 추적 과정 -물체 추적을 수행하기 위하여 새로 검출한 물체의 바운딩 박스와 이전 프레임까지 추적중인 물체의 바운딩 박스 안에 있는 라이다 포인트 데이터 추출 -추출된 라이다 포인트 데이터로부터 특징값 추출 후 딥러닝을 이용한 유사도를 측정하고 물체 ID 부여
2. 라이다 기반 3차원 물체 추적 기술
라이다 데이터의 특징 추출 방법 -새로 검출된 물체와 추적하고 있던 물체로부터 추출된 3차원 라이다 포인트 클라우드 정보를 포인트넷 기반의 딥러닝 모델을 이용하여 특징값 추출 -포인트넷 기반의 딥러닝 모델은 정보의 손실 없이 모든 포인트 클라우드 데이터를 사용하여 유용한 특징값 추출 가능
유사도 측정 및 검출 결과 연결 -전체적인 물체 연결 과정은 2차원 물체 추적 기술과 유사 -Siamese딥러닝 모델을 사용해서 새로 검출된 물체의 특징값과 추적중인 물체의특징값을 비교하고 두 벡터의 거리를 계산하여유사도 평가(일반적으로 유사도는 0과 1사이의 실수값으로 출력됨) -검출 결과의 모든 쌍에 대해 유사도를 계산한 후 헝가리안 알고리즘을 적용하여 연결 결과 출력
3. 라이다 기반 3차원 물체 추적 기술 사례★
mmMOT 방법 -검출된 물체와 추적 중인 물체의 라이다 포인트 데이터를 추출 후 포인트넷을 적용해서 특징값 추출 -CNN 네트워크를 적용해서 두 물체의 유사도를 판별하고 선형 프로그램의 최적화 기법을 적용해서 검출 결과 연결
GNN3DMOT 방법 -검출 결과에 대한 특징을 추출하기 위해 포인트넷을 적용했을때 얻은 특징뿐만 아니라 그 물체의 시간적인 움직임 정보도 LSTM 네트워크를 통해 추출해서 추가적으로 사용 -헝가리안 알고리즘 대신 그래프 뉴럴 네트워크 모델(GNN)을 사용해서 더 정확한 검출 결과 연결 수행
[3차원 물체 검출/추적 통합 기술 심화]
1. 3차원 물체 검출/추적 통합 기술 개요
기존의 인지 기술에서는 물체 검출과 추적 기술을 별도로 설계 -물체 검출에서는 센서 데이터의 공간적 정보 활용, 물체 추적 기술에서는 시간적 정보 활용
환경의 시공간적 정보를 동시에 활용하여 검출/추적 기술의 통합설계 필요 -물체 검출에서는 물체의 시간적 움직임 정보 활용 -물체 추적에서의 물체의 공간적 특징 정보 활용 -물체 검출, 추적 기술의 서로 정보 교환 및 통합 최적화
2. 3차원 물체 검출/추적 통합 기술
물체 검출에서의 시간적 정보 활용 -카메라 영상을 CNN에 통과하여 나온 특징값을 사용해서 각각의 입력 영상에 대해 검출 결과를 얻게 됨 -비디오 영상을 한꺼번에 처리하여 시공간적 정보를 활용해서 검출 성능 개선
시간적 정보를 활용하는 두가지 전략 -비디오 영상에서 물체 움직임에 의해 발생하는 다양한 왜곡 발생 : 시간적으로 얻은 특징값들을 융합하여 특정 영상 프레임의 퀄리티 저하에도 강인한 검출 결과 달성 -물체의 움직임 패턴을 분석하여 물체 검출의 성능 향상 : RNN이나 LSTM 모델을 사용하여 특징값을 추출한 후 물체 검출에 활용
물체 추적에서의 물체의 공간적 특징 정보 활용 -물체 검출 시 CNN을 이용하여 특징값을 추출하여 물체 추적의 연결 수행에 재사용
센서 융합을 통해 물체 검출을 수행한 경우 다중 센서로부터 추출했던 특징값들을 추적에 사용하여 연결 성능 개선
물체 검출과 물체 추적 기술이 서로 유용한 정보 교환
물체 검출에서 사용했던 공간적인 정보들이 추적에서 활용 가능
물체 추적에서 사용했던 시간적 정보들이 다시 정확한 물체 검출을 수행하는데 사용
물체 검출과 추적을 통합하는 딥러닝 모델의 종단간(end-to-end)학습을 통해 최적의 인지 성능 달성
[카메라, 레이더 센서융합 딥러닝 기술 심화]
1. 카메라, 레이더 센서융합 딥러닝 기술 개요
레이더는 자율주행에서 많이 사용되고 있으나 높은 오탐률이 단점
딥러닝이 적용되면서 최근 카메라 영상 기반의 물체 검출 기술의 성능이 급속도로 발전
카메라, 레이더 센서는 라이다 센서에 비해 가격이 저렴하여 현재 2단계 수준의 자율주행 기능에서 사용
카메라 센서가 제공하는 영상 정보와 레이더 센서가 제공하는 거리 측정 정보를 융합하여 신뢰성 높은 물체 검출 가능
카메라, 레이더 센서 융합 전략 -카메라 센서 중심의 융합 방법 : 카메라로 2차원 물체 검출 결과를 생성해내고 레이더 센서 정보를 읽어서 가져와서 정밀한 거리 정보 제공
-레이더 센서 중심의 융합 방법 : 레이더 센서를 이용하여 조감도 영역에서 물체를 검출한후 카메라 정보를 이용하여 레이더 검출 결과의 오류 수정
카메라, 레이더 센서 융합 전략 -특징값 중심의 융합 전략 : 4D 이미지 레이더와 같은 고해상도 레이더의 경우에 주로 적용 : 레이더 데이터로부터 추출한 특징값을 카메라로 도출된 CNN 특징값과 융합하여 융합된 특징값을 이용하여 물체를 검출 : 카메라, 라이다 센서 융합 전략과 유사
2. 카메라, 레이더 센서융합 딥러닝 기술 사례
2019년 'EuRAD'라는 학회에서 발표 : 카메라, 레이더 융합을 통한 3차원 물체 검출 방법 -딥러닝을 적용하여 카메라, 레이더 센서 융합 수행 -레이더 포인트 클라우드 데이터를 조감도 영역에서의 특징 지도로 변환후 조감도 영역에서 융합 수행 -융합된 특징값을 기반으로 추가적인 뉴럴네트워크 구조를 적용하여 3차원 물체 검출 수행
[카메라, 라이다 센서융합 딥러닝 기술 심화]
1. 카메라, 라이다 센서융합 딥러닝 기술 개요
3단계 이상의 자율주행에서 카메라와 라이다 센서는 인지를 위한 핵심 센서로 간주되고 있음
두 센서의 장단점을 보완하기 위해 카메라, 라이다 센서 융합 기술이 필요 -카메라 : 물체를 인식하기 위한 풍부한 정보 제공, 거리 정보 부정확 -라이다 : 정확한 거리 정보 제공, 해상도가 카메라만큼 높지 않음
최근 카메라, 라이다 센서 융합을 위한 다양한 딥러닝 기법이 연구되고 있음
2. 카메라, 라이다 센서융합 접근 방법
카메라 중심의 센서융합 기술 : 카메라를 주센서로 사용하고 라이다 정보를 부가적으로 융합하는 기법 -카메라 영상에 CNN 기반의 딥러닝 모델을 적용하여 물체에 대한 2차원 박스 검출 -카메라 영상의 2차원 박스에 해당하는 3차원 공간의 영역을 프러스텀이라고 부름 -검출된 2차원 박스에 해당하는 프러스텀에 존재하는 라이다 포인트들을 추출 -추출된 라이다 포인트들을 포인트넷으로 처리하여 3차원 검출 정보를 얻어냄
카메라 중심의 센서융합 기술 사례 -프러스텀 포인트넷 방법(CVPR18) --카메라 영상에 2D CNN 물체 검출 기법을 적용하여 2차원 영역 추출한 후 2차원 영역을 3차원으로 변환하여 프러스텀 안에 있는 포인트들에 대해 3차원 영역 분할 수행
물체가 아닌 배경을 마스킹하고 물체 부분에 포인트넷을 적용하여 3차원 박스 추정 -카메라, 라이다 특징값 융합 기술 -카메라와 라이다 센서 각각으로부터 물체에 대한 특징값을 추출한 후 융합하여 물체 검출 -카메라 영상에 CNN을 적용하여 특징값 추출 -라이다 포인트 클라우드를 3차원 복셀 구조를 기반으로 인코딩
앵커박스를 기반으로 융합하는 방법과, CNN으로 얻은 2차원 카메라 특징지도를 3차원 공간으로 투영하여 융합하는 방법이 있음 -예>AVOD(IROS 18), Cont-Fuse(ECCV 18), MMF(CVPR 19), 3D-CVF(ECCV 20)
카메라, 라이다 특징값 융합 기술 사례
3D-CVF 방법
--카메라 센서 데이터를 CNN을 적용하여 2차원 특징 지도 도출 --2차원 특징 지도를 3차원 복셀 구조로 투영하여 새로운 3차원 특징지도 구성 --라이다 데이터를 인코딩하여 얻은 특징지도와 융합 후 새로운 특징값으로 3차원 물체 인지 수행
[고성능 센서 차량 네트워크 기술]
1. 고성능 센서 차량 네트워크 기술 개요
CAN/CAN-FD : 1Mbps, 현재 가장 많이 사용하는 차량 네트워크, Bus토폴로지 방식
자율주행 센서로부터 유입되는 데이터량 증가 -고해상도 카메라 영상, 고해상도 라이다 데이터로부터 발생되는 트래픽을 관리할 수 있는 네트워크 필요 -CAN ECU와 이더넷 ECU를 통합 관리할 수 있는 기술 필요 -Bus 기반 이더넷과 P2P 기반 Serdes 방식이 혼합된 형태로 표준화 진행
Serdes -P2P 기반의 고속 차량 통신 기술 -기존의 고해상도 Display 등의 통신에 사용 -고해상도 카메라 센서로부터 얻은 비디오 데이터 전송을 위해 고려중 -최대 16Gbps까지 전송 속도 지원
차량 네트워크 발전 방향 -고속 BUS 네트워크 전송 기술 -P2P 고속 데이터 전송 기술 ->혼합 사용 및 호환성 지원에 대한 연구 필요
[고정밀 지도 관리 기술 심화]
1. 고정밀 지도 기술 개요
자율주행을 위해서는 cm 수준의 정확도를 갖는 고정밀 지도 필요
사전에 MMS(Mobile mapping system) 차량을 이용하여 고정밀 지도를 제작 -지형 지도 : 주변 지형의 형태를 직접 센서데이터를 사용하여 구성
-시맨틱 지도 : 측위에 관련된 특정 지형, 도로 정보, 랜드마크 등을 지형 지도에 추가해놓은 형태
자율주행차량은 측위 기술을 수행하여 고정밀 지도에서의 자신의 위치를 추정 -Odometry 기술 -맵매칭 기술
2. 고정밀 지도 구성
고정밀 지도 구성 -도로의 구조 및 공간적 구성(예:주행차로, 교차로, 차로분기점, 차로합류점 등) -차량의 주행공간에 대한 정보 -도로의 내부 및 주변에 존재하는 다양한 형태의 표시 -표지 및 시설물
표준화 -ISO TC 204 : 지능형 교통체계(ITS) 분야에 요구되는 아키텍처, 통신 및 서비스에 대한 표준화를 논의하는 기구, 자율주행, 협력주행을 위한 지도에 대한 표준화 진행 중 -OGC(Open Geospatial Consortium) : 정밀 지도 관련 다수의 표준화 진행 중 -NDA(Navigation Data Standart) : 차량 OEM 회사, 지도 공급자 및 내비게이션 서비스 업체들이 모인 그룹으로 ADASIS라는 자율주행을 위한 지도 표준 발표 -국내에서는 현대엠엔소프트, SKT등에서 자체 모델을 구축하고 있고 국토지리정보원에서도 고정밀 지도에 대한 표준화 진행 중
3. 고정밀 지도 관리 기술
LDM(Local Dynamic Map) 동적 정보 시스템
고정밀 지도의 갱신 및 관리 -시간에 따른 환경 변화로 갱신과 관리 필요 -클라우드 기반 지도 관리 플랫폼 요구됨 -자율주행차, 인프라, 엣지 등에서 수집한 환경 정보를 온라인으로 갱신하는 기술 필요 -업데이트된 고정밀 지도를 V2X 등의 통신 방법을 사용하여 자율주행차에 전달
시맨틱 지도 관리 -AI 기술이 측위에도 적용되면서, 딥러닝의 출력(Neural representation)을 시맨틱 지도의 임베딩 데이터로 활용하는 연구 진행중
[고정밀 지도 기반 측위를 위한 딥러닝 기술 심화]
1. 고정밀 지도 기반 측위 기술 개요
고정밀 지도 기반의 측위 기술 -고정밀 지도의 정보와 차량이 실시간으로 수집한 정보를 이용하여 차량의 현재 위치를 알아내는 기술
측위 기술의 구성 -Odometry 기술 : 차량의 이전의 위치에서부터 상대적으로 얼마만큼 이동했는지를 측정하는 방법 -맵매칭 기술 : 차량 센서 데이터와 지도 데이터를 정합하여 지도 위의 차량 위치를 추정하는 방법
기존 측위 기술의 한계 -기존의 모델 기반의 방법들은 이상적인 상황에서는 센서정보를 이용하여 정확하게 자신의 위치를 추정할수있음 -실제로는 부정확한 세서 측정값, 실제와 잘 맞지않는 시스템 모델, 복잡한 환경의 다이내믹스, 제약사항 등이 측위 기술의 성능에 영향을 미침 -Odometry 추정 : 저가 관성항법장치의 오차가 크고 시간에 따라 누적, Visual odometry의 고전적인 기법들은 카메라 영상의 취득 퀄리티에 영향을 받음 -맵매칭 : 부정적인 센서 데이터와 주변 환경의 변화로 인해 측위 정확도가 저하되는 문제 발생
2. 측위를 위한 딥러닝 기술
딥러닝 기술 -데이터 기반의 접근 방법, 수많은 데이터를 사용하여 복잡한 입출력 관계를 모델링 -데이터를 활용하기 때문에 새로운 환경에 대해 측위 알고리즘의 자연스러운 진화가 가능
딥러닝 기반 Odometry 기술 -Visual odometry 기술 : 카메라 영상으로부터 카메라의 움직임을 추적하여 차량의 위치 상태를 추정 ex) DeepVO -라이다 odometry 기술 : 라이다 포인트 클라우드 데이터의 움직임을 추적하여 위치의 변화를 추정
딥러닝 기반 맵매칭 기술 -이미 생성된 지도 정보와 센서를 정합 -디스크립터 매칭 기술 : 센서 데이터로부터 특징점들을 검출한 후 주변 환경을 압축하여 표현하는 표현자(Feature descriptor)를 추출, 센서로부터 얻은 표현자와 지도에 임베딩된 표현자를 정합하여 차량 위치 추정 - 종단간 학습: 전체 측위 시스템을 위한 추적 정확도를 최대화 하도록 종단간(end to end) 학습을 함
[자율주행을 위한 예측 기술 심화]
1. 고전 예측 기술의 한계
경로 예측 기술 -자율주행차가 안전한 주행을 하기 위하여 동적 객체들의 과거 경로와 주변 상황들을 반영하여 의도나 미래의 거동을 예측하는 기술
고전적인 예측 기술 -등속도 또는 등가속도 모델에 의한 예측 -선형보간법에 의한 예측 기법 -칼만필터와 같은 통계적 예측 모델 사용
고전 예측 기술의 한계 -동적 객체들의 거동은 객체들의 의도, 주변의 도로 및 주행 상황, 객체간 상호작용 등의 다양한 요소에 의해 영향을 받음 -예측 결과는 하나의 최적의 경로로 출력되기보다는 여러개의 가능 경로가 확률과 함께 나타나는 것이 합리적임 -고전 예측 기술에서는 이러한 문맥적 정보들의 활용이 어렵고 하나 이상의 다양한 예측 결과를 도출하기 어려운 문제점이 있음
2. 딥러닝 기반 차량 경로 예측 기술
RNN(recurrent neural network)에 기반한 차량 경로 예측 -순차적인 시계열 데이터를 해석하기 위한 RNN 또는 LSTM 모델을 이용하여 과거의 차량 경로 데이터를 입력으로 받아 미래의 차량 경로 데이터를 생성 -인코더-디코더 구조로 구성 -딥러닝의 뛰어난 표현력을 이용하여 기존의 칼만필터 등에 비해 개선된 예측 정확도를 달성
동적 객체 간의 상호작용을 고려한 차량 경로 예측 -타겟 차량과 주변 동적 차량들의 과거 경로들을 딥러닝 모델에 입력하여 상호작용을 고려한 예측 결과를 출력
주변 도로, 정적 환경을 고려한 차량 경로 예측 -주변의 도로나 정적 환경을 2차원 영상으로 구성하여 특징값을 추출하고 이를 차량 경로의 특징값과 융합하여 경로 예측을 수행
[상황 예측을 위한 딥러닝 기술 심화]
1. 자율주행을 위한 상황 예측의 필요성
자율주행차가 위험이나 충돌을 방지하기 위해서는 미래에 나타날 상황을 예측해야함
휴먼 운전자는 본능적으로 주변에 대한 인지 결과를 바탕으로 미래에 일어날 상황을 예측하여 대응
자율주행의 안정성 향상을 위해 다양한 종류의 동적 객체들의 움직임 예측을 기반으로 다양한 주행 상황에 대한 예측이 필요
2. 딥러닝 기반 상황 예측
딥러닝 기술을 사용하여 센서 데이터로부터 동적 객체의 위치 뿐만 아니라 상태 정보도 추출
카메라 영상에 CNN을 적용하여 보행자의 자율주행차 주시 여부 또는 전방 차량의 방향지시등 상태 등 파악 가능
RNN이나 LSTM 모델을 이용하여 동적 객체의 위치, 상태 등의 순차적인 변화를 분석하여 미래의 주행 상황 예측
보행자 거동 예측을 위한 딥러닝 기술(MediaPipe Pose Estimation) -비디오 영상을 분석하여 휴먼의 행동을 분류하고 예측하는 딥러닝 모델 -카메라 영상으로 휴먼의 중요 관절에 해당하는 키포인트를 추출하는 자세추정 딥러닝 모델 -과거의 휴먼의 자세와 상태 정보로부터 미래의 휴먼의 자세와 상태 정보를 예측하는 딥러닝 모델
비디오 예측 기술 -동영상의 다음 프레임을 직접 예측하는 기술 -가까운 미래에 대한 예측은 가능하나 먼 미래에 대한 경우 동적 객체들의 움직임 등에 대한 시맨틱 정보들을 활용해야 정확한 예측이 가능 -포즈의 정답(Ground truth)에 주어지지 않는 비지도 학습 방법에 대한 연구가 활발함
의도 예측 -동적 객체 움직임의 목표 또는 의도를 예측하는 작업 -동적 객체의 실제 경로를 예측하는 것보다 동적 객체의 목표방향 또는 의도를 예측하게 되면 예측 작업의 복잡도를 간소화시킬 수 있는 장점 -의도 예측 결과를 조건으로 하여 경로를 예측하여 더 높은 예측 정확도 달성 가능